Agentic AI in 2026: What I’ve Learned Building Multi-Agent Systems That Actually Work
Daffa Albari
Author
The gap between the demo and the deployment is where most agent projects go to die. Here’s what nobody tells you.
I need to be honest with you.
If you’ve been scrolling through LinkedIn lately, you’d think every company on the planet has deployed an army of AI agents that are autonomously running their business, closing deals, writing code, and probably making coffee too.
That’s not what I’m seeing.
What I’m seeing — from the trenches, as someone who actually builds these systems — is a lot of broken pipelines, hallucinating agents, and teams quietly rolling back to simpler solutions after burning through months of engineering effort.
And look, I’m not here to tell you agentic AI is dead. It’s not. Some of my most exciting work this year has been in multi-agent architectures. But the conversation around agents has gotten so detached from engineering reality that I think it’s worth pulling things back to earth.
So let me walk you through what I’ve actually learned.
The Promise Was Seductive
The pitch was clean: instead of one monolithic LLM doing everything, you break the problem into pieces. One agent plans. Another executes. A third reviews the output. They talk to each other, coordinate, and deliver results that no single model could produce alone.
It sounds elegant. And in a demo, it looks incredible.
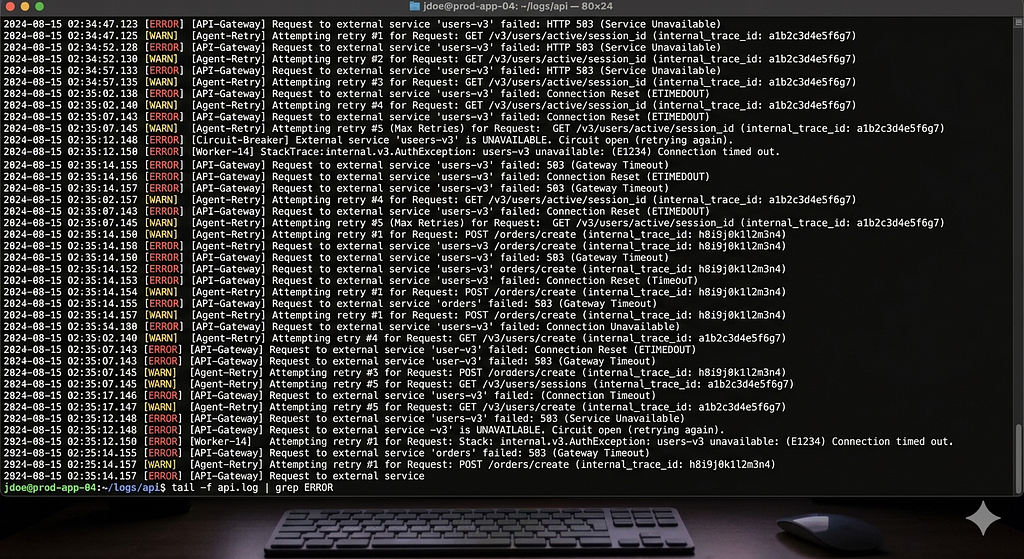
The problem is that demos don’t have edge cases. Demos don’t run at 3 AM when your orchestrator agent decides to loop infinitely because it interpreted ambiguous user input as a recursive instruction. Demos don’t deal with the downstream cost of an agent confidently generating wrong SQL that corrupts a staging database.
I’ve watched it happen. More than once.
Why Single Agents Break Down
Before we talk about multi-agent systems, let’s acknowledge why we need them in the first place.
A single LLM — no matter how capable — hits a wall when you ask it to do too much in one pass. I call this the “context overload” problem, though you’ll hear fancier names in research papers.
Here’s what it looks like in practice.
You give an agent a task: “Analyze this dataset, generate a report, and email it to the stakeholder with a summary.” Straightforward, right? But the agent has to hold the data schema in context, remember the formatting requirements, handle the email API integration, and produce coherent prose — all while maintaining its chain of reasoning.
What actually happens is the model starts cutting corners. The analysis gets shallow. The report formatting drifts. The email summary contradicts the report because by the time the model got to writing the email, it had functionally “forgotten” the nuances from the analysis step.
This isn’t a model intelligence problem. It’s an architectural one.
And this is where multi-agent thinking starts to make sense — not as a hype cycle, but as a genuine engineering solution.
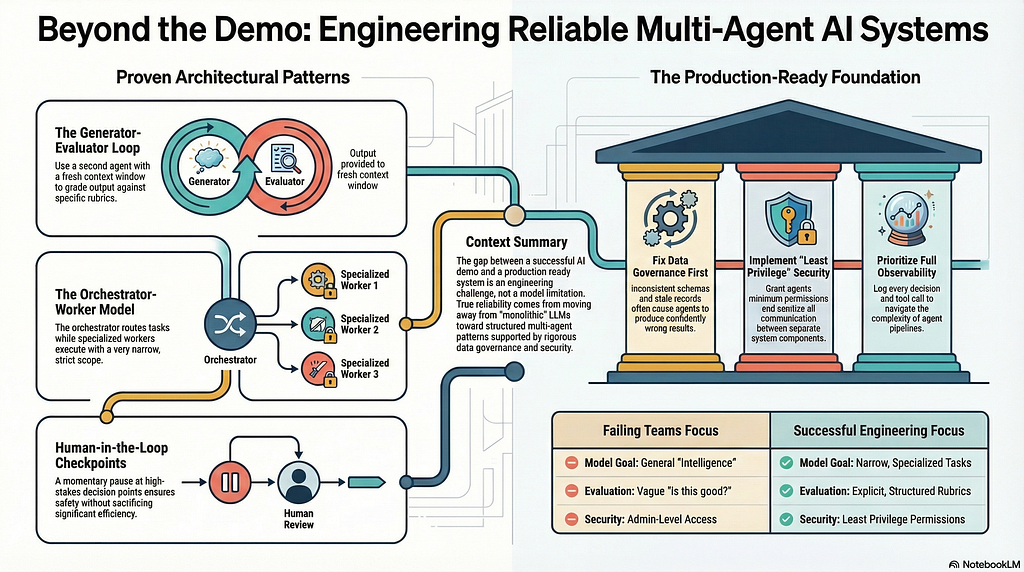
The Patterns That Actually Work
Over the past year, I’ve landed on a few multi-agent patterns that have survived contact with production. Not all of them are glamorous. Some are downright boring. But they work.
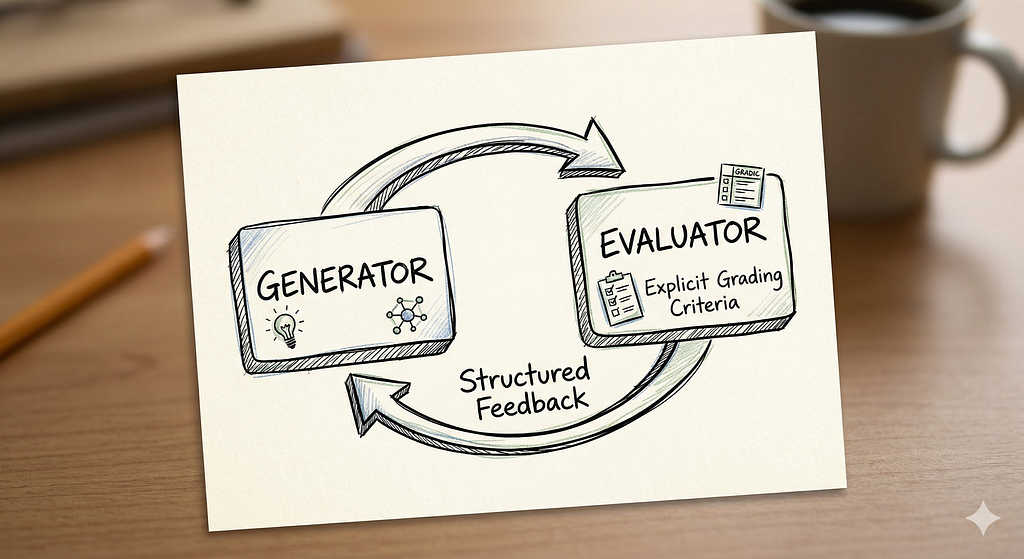
The Generator-Evaluator Loop
This one has been my workhorse.
The idea is simple: one agent generates output, and a second agent evaluates it against explicit criteria. If the output fails evaluation, it goes back to the generator with structured feedback. Rinse, repeat.
What makes this different from just “asking the model to check its own work” is separation. The evaluator has its own system prompt, its own grading rubric, and its own context window. It’s not polluted by the generator’s reasoning chain. It comes in fresh.
I’ve used this pattern for everything from code generation to document drafting, and the quality improvement is dramatic. Not because either agent is smarter, but because the feedback loop forces iteration with clear criteria instead of vague self-correction.
The key detail nobody mentions: your grading rubric matters more than your model choice. I’ve seen teams spend weeks fine-tuning model selection while their evaluation criteria was basically “is this good?” — a three-word rubric that tells the evaluator nothing.
Be specific. “Does the SQL query use parameterized inputs? Does it handle null values in the join column? Does it include a LIMIT clause for safety?” That’s a rubric. “Is the query correct?” is a wish.
The Orchestrator-Worker Pattern
This one handles complexity by breaking big tasks into smaller subtasks, each handled by a specialized worker agent.
Think of it like a project manager who doesn’t write code but knows exactly which developer to assign each ticket to. The orchestrator decomposes the user’s request, routes subtasks to the appropriate worker agents, collects results, and assembles the final output.
Where teams get this wrong: they make the orchestrator too smart. They load it with complex routing logic, conditional branching, retry policies — and suddenly the orchestrator itself becomes the bottleneck. It starts making bad routing decisions because its own prompt is overloaded.
My rule of thumb: if your orchestrator prompt is longer than two pages, you’ve gone too far. Keep the orchestrator dumb. Its job is decomposition and routing, not decision-making. Let the workers be the experts.
One thing I’ve found surprisingly effective is giving each worker agent a very narrow scope and a very strict output format. The summarization worker only summarizes. The data extraction worker only extracts. No worker tries to be helpful beyond its lane. This feels limiting until you see how much more reliable the whole system becomes.
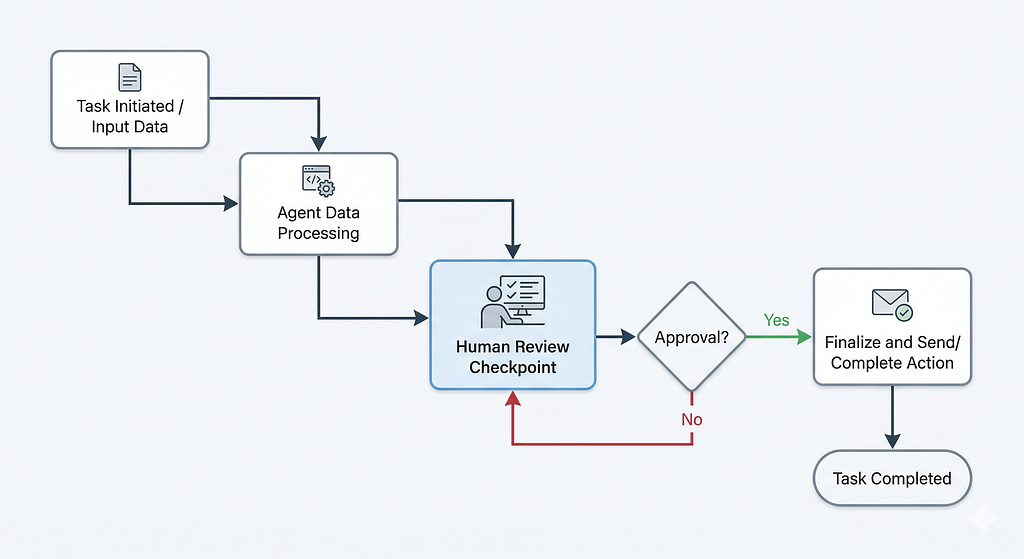
The Human-in-the-Loop Checkpoint
I know, I know. This doesn’t sound like cutting-edge AI architecture. But hear me out.
The most reliable agent systems I’ve built all have moments where the system pauses and asks a human to confirm before proceeding. Not for every step — that would defeat the purpose. But at high-stakes decision points.
The mistake I see teams make is treating human-in-the-loop as a failure of the technology. “If the agent can’t do it autonomously, what’s the point?” But that framing misses the reality: some decisions carry enough risk that no amount of model improvement justifies full automation. At least not yet.
I think of checkpoints as guardrails, not crutches. The agent does 90% of the work. The human spends 30 seconds reviewing a critical output before the system proceeds. Total time saved compared to doing it manually? Still enormous.
The Data Problem Nobody Wants to Talk About
Here’s the uncomfortable truth that I keep running into: most agent failures aren’t agent failures. They’re data failures.
Your agent can only be as reliable as the data it operates on. And most enterprise data is a mess. Inconsistent schemas, stale records, missing fields, duplicated entries. Feed that into an agent pipeline and you get confidently wrong outputs at scale.
I spent three weeks debugging an agent system last quarter that kept producing contradictory reports. The agent architecture was solid. The prompts were well-structured. The problem? The underlying database had two different tables tracking the same metric with slightly different calculation methods. The agent was pulling from both and averaging them — which technically made sense given its instructions, but produced numbers that confused everyone.
The fix wasn’t an agent fix. It was a data governance fix.
If you’re planning to build agent systems, start with your data. I know it’s not exciting. I know nobody writes Medium articles titled “I Fixed My Data Pipeline and It Changed My Life.” But it’s the foundation everything else rests on.
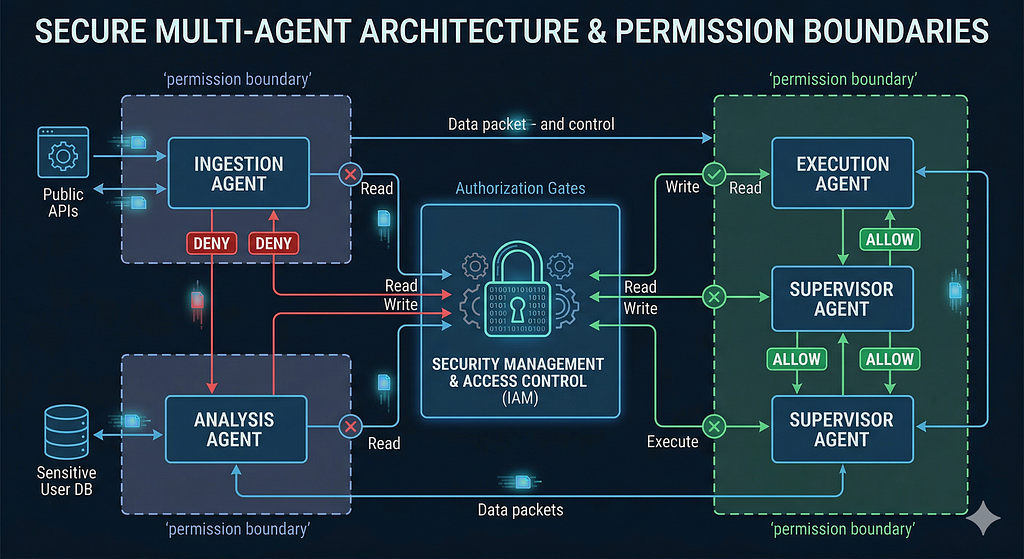
Security Is Not an Afterthought
Prompt injection in agent systems is a real and present danger, and I don’t think enough teams are taking it seriously.
When you give an agent access to tools — APIs, databases, file systems, email — you’re creating an attack surface. A carefully crafted input can trick an agent into executing unintended actions. And in a multi-agent system, where agents pass messages to each other, a single injected prompt can cascade through the entire pipeline.
I’ve adopted a few practices that have helped:
Least privilege, always. Every agent gets the minimum permissions it needs. The summarization agent doesn’t need write access to the database. The email drafting agent doesn’t need access to the financial API. This sounds obvious, but I’ve reviewed systems where every agent had admin-level access because “it was easier during development” and nobody locked it down before deployment.
Input sanitization between agents. Treat inter-agent communication like you’d treat user input — with suspicion. Validate the format. Check for unexpected instructions embedded in the data. Don’t assume that because Agent A produced the output, it’s safe for Agent B to consume blindly.
Audit logging everything. Every agent action, every tool call, every decision point — logged. When something goes wrong (and it will), you need the trace to understand what happened. This has saved me more debugging hours than any other single practice.
What’s Actually Worth Building Right Now
After everything I’ve said, you might think I’m down on agents. I’m not. I’m just tired of the gap between the marketing and the engineering.
Here’s where I’ve seen multi-agent systems deliver genuine, measurable value:
Internal tooling and automation. Agents that handle repetitive internal workflows — processing invoices, categorizing support tickets, generating status reports from multiple data sources. These are constrained environments with structured data and clear success criteria. Perfect for agents.
Code review and quality assurance. The generator-evaluator pattern shines here. One agent writes code, another reviews it against coding standards, a third runs test cases. The output isn’t perfect, but it catches 70–80% of issues before a human reviewer touches it. That’s a massive time saver.
Research and synthesis. Agents that pull information from multiple sources, cross-reference findings, and produce structured summaries. The key is defining the output format tightly so the synthesis step doesn’t become a hallucination playground.
Where I’d be cautious: anything customer-facing with high stakes, anything involving financial transactions, and anything where the agent’s mistake would be expensive or embarrassing to reverse. Not because the technology can’t get there, but because it’s not there yet for most teams.
The Honest Roadmap
I think we’re about 12–18 months away from agent systems being genuinely reliable for broader production use. Not because models need to get dramatically smarter — they’re already quite capable. But because the surrounding infrastructure needs to mature.
We need better observability tools for agent pipelines. We need standardized protocols for agent communication (MCP is a step in the right direction, but we’re early). We need frameworks that handle failure gracefully instead of cascading errors. And we need engineering teams to stop treating agent development like a hackathon project and start treating it like systems engineering.
The companies that will win with agentic AI aren’t the ones deploying agents the fastest. They’re the ones building the boring stuff first — the data foundations, the security layers, the monitoring systems — and then layering agents on top of infrastructure that can actually support them.
Wrapping Up
If you take one thing from this article, let it be this: the gap between an agent demo and an agent in production is not a technology gap. It’s an engineering gap.
The models are capable enough. The patterns exist. The tools are improving rapidly. What’s missing is the unglamorous work of building reliable systems around unreliable components — which, if you think about it, is what software engineering has always been about.
We just need to apply the discipline we already have to this new paradigm.
Build small. Test obsessively. Log everything. Keep humans in the loop where it matters. And for the love of everything, fix your data before you blame the agent.
If you found this useful, I write about AI engineering from the practitioner’s side — no hype, just what I’m learning in the trenches. Follow me for more.
Have questions or want to share your own multi-agent war stories? Drop them in the comments. I read all of them.

Originally published on Medium
View original article →